R might not be the most obvious tool when it comes to analysing audio data. However, an increasing fiber internet speed and the number of packages allows analysing and synthesising sounds. One of such packages is seewave. Jerome Sueur, one of the authors of seewave, now wrote a book about working with audio data in R. The book is entitled Sound Analysis and Synthesis with R and was published by Springer in 2018. I highly recommend it to anyone working with audio data.
The book starts with a general explanation of sound. Then it introduces R to readers who have no experience using it. Over the 17 chapters the author describes basic audio analyses that can be conducted with R. The underlying concepts are explained using both mathematical equations and R code. There is also some material on sound synthesis, but this is a minor point when compared to the space devoted to the analysis. Additional materials include sound samples used across the book.
As mentioned before the main topic of the book is the analysis of sound, predominantly in scientific settings. Researchers (or data scientists) typically would want to load, visualise, play, and quantify a particular sound that they work on. These basic steps are desribed in this book with code examples that are simple to follow and richly illustrated with R-generated plots. Check the book preview here.
If you ever need to paste, delete, repeat or reverse audio files with R then recipes for these tasks can be found in this book. The book contains twenty DIY Boxes which show alternative ways to use already coded functions and demonstrate new tasks. These boxes cover topics ranging from loading audio files, plotting to frequency and amplitude analysis.
Even though the author created his own package, the book shows how to use a wide range of audio-specific R package like tuneR or warbleR.
I can only wish that this book had been released earlier. It would have saved me a lot of pain conducting audio analyses.
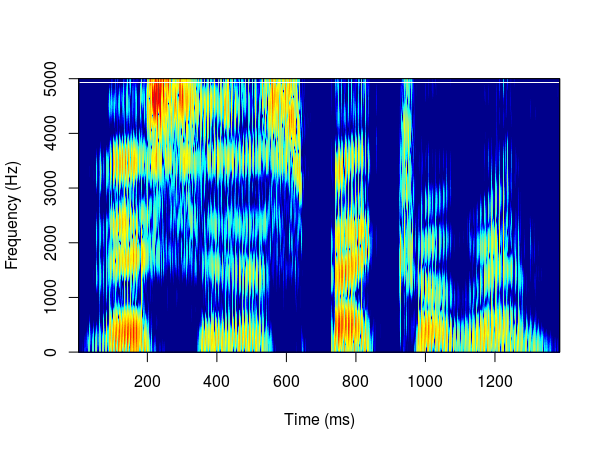
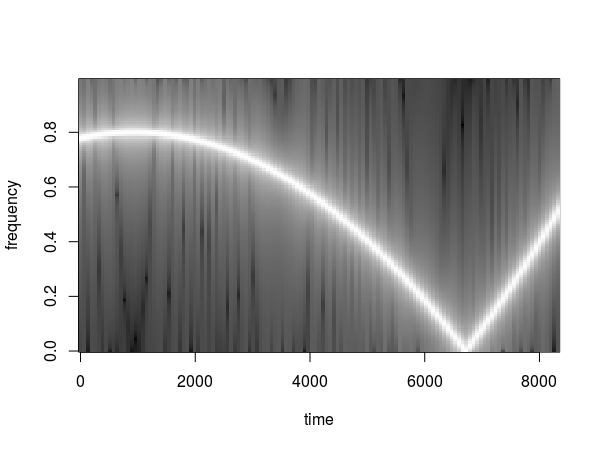
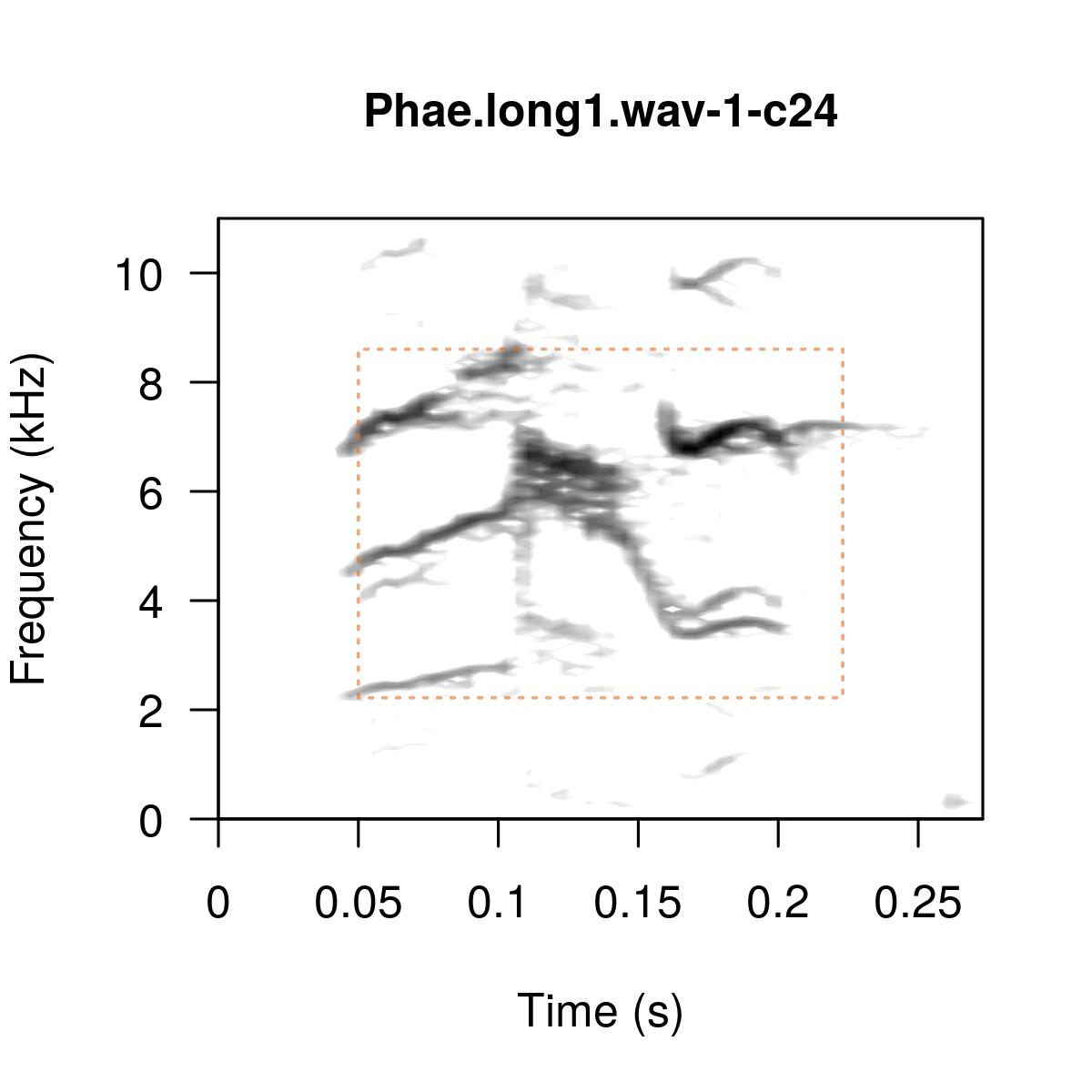
Creating a spectrogram is a basic step in every analysis of audio signals. Spectrograms visualise how frequencies change over a time period. Luckily, there is a selection of R packages that can help with this task. I will present a selection of packages that I like to use. This post is not an introduction to spectrograms. If you want to learn more about them then try other resources (e.g. lecture notes from UCL).
The examples shown below came mostly from the official documentation and were kept as simple as possible. The majority of functions allow further customisation of the plots.
phonTools
seewave
seewave and ggplot2
signal
soundgen
warbleR
hht
Creating a spectrogram from the scratch is not so difficult, as shown by Hansen Johnson in this blog post. Another solution was provided by Aaron Albin.
Praat is a workhorse of audio analysis. It is a standalone software, but there is also an R controller called PraatR, that allows calling Praat functions from R. It is not the easiest tool to use so I will just mention it here for reference.
I am pretty sure that there are more packages that allow creating spectrograms but I had to stop somewhere. Feel free to leave comments about other examples.
Homer2 needs a particular format of a .nirs file that cannot have consecutive triggers (also called Marks in Hitachi files).
hitachi2nirs Matlab script also removes the markers but I wanted to recreate the whole process and be sure that I’m doing it correctly. Answering Yes to the question Do you want to remove the marker at the end of each stimulus? y/n will run the following code:
To remove the triggers/markings in R follow the steps below.
and a plot showing raw data in one channel (quite noisy) with all the triggers.
This shows several triggers (all plotted using red colour). I will only keep trigger ‘2’ to mark the beginning of a block. The first step is cleaning the data by removing all but trigger ‘2’.
Which results in fewer events
It turned out that there were two ‘2’ triggers next to each other. That’s because ETG-4000 does not allow odd triggers next to each other, e.g. 212 is invalid, but 22111122 is valid. I wrote a function (soon incorporated into fnirsr package) that deals with this problem.
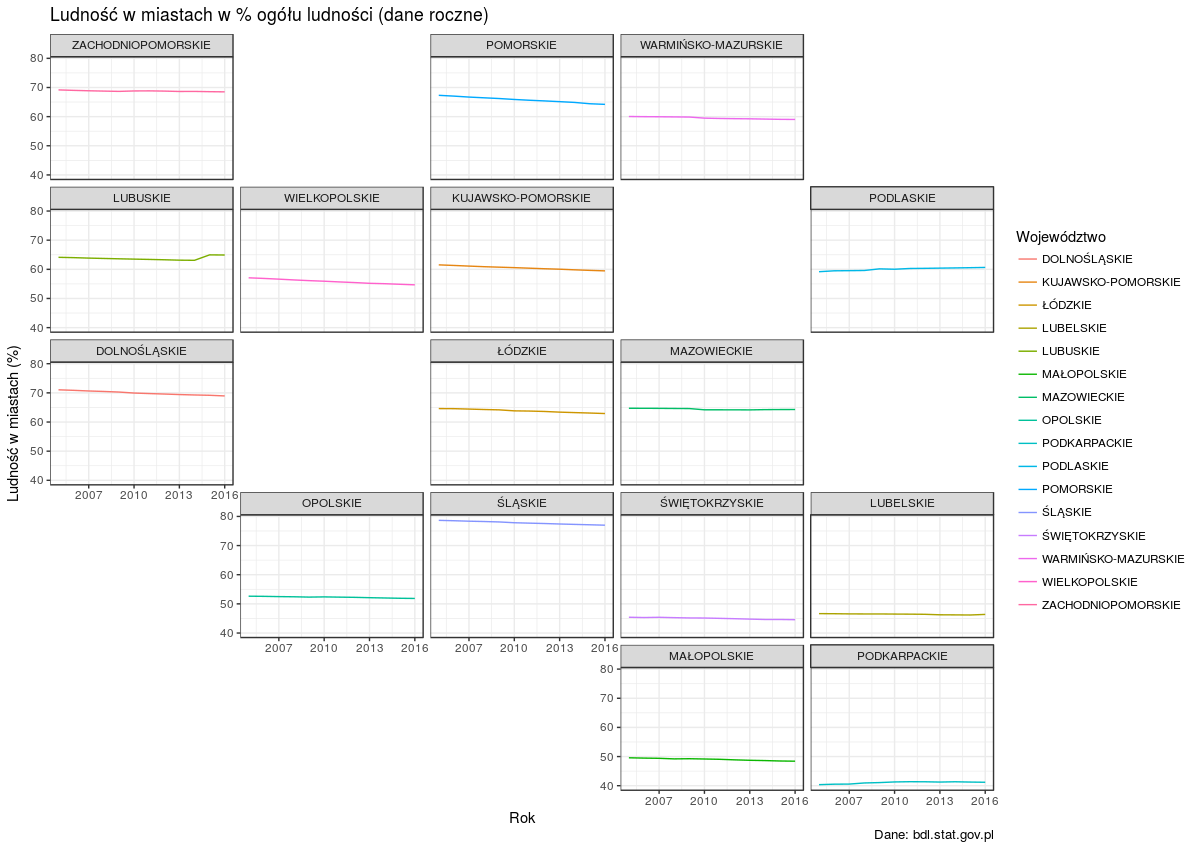
Niedawno odnalazłem ciekawy pakiet geofacet, który umożliwia rozmieszczenie wykresów zgodnie z ich pozycją na mapie. Główna funkcja facet_geo() zastępuje facet_wrap() z ggplot2. Polska mapa jeszcze nie jest dostępna w standardowym pakiecie geofacet, ale mam nadzieję, że już wkrótce tam się znajdzie, bo dodałem ją na GitHubie.
Stworzyłem siatkę z koordynatami poszczególnych województw. Wykresy z pakietem geofacet mogą wyglądać tak:
Rozmieszczenie województw nie jest idealne, ale pakiet geofacet umożliwia użycie własnych ustawień.
Dane pochodzą z Banku Danych Lokalnych (XLS - tablica przestawna)
Zoopla allows a limited access to its API providing the latest property prices and area indices. I created a package in R that allows querying this database. See the GitHub documentation or zooplaR’s page for the latest info.
You can easily get prices in the last couple of months or years for a particular postcode, outcode or area:
Given, the limit number of queries, it might be worth double-checking the results with the property widget offered by Zoopla (redirects to zoopla.co.uk).
It doesn’t have as many options as the API and obviously is not automatic but it’s worth using for a sanity check.
In my previous post I showed how to enable MATLAB in Jupyter notebooks on Windows. Now it’s time for GNU/Linux (Ubuntu).
My main issue with enabling new kernel was having initially installed two Anacondas and two Python versions (2.7 and 3.5). After a lot of frustration, I decided to remove both Anacondas and have a clear install of the latest Anaconda with Python 2.7 and 3.5. In this tutorial I assume that Jupyter and MATLAB are already installed on your system.
Using the right environment
Although the official MATLAB website states that Python-MATLAB engine works with Python 2.7, 3.4, 3.5 and 3.6, I struggled to install it using Python 3.5. If you try to install it with a 3.5 version, you will see the following error:
OSError: MATLAB Engine for Python supports Python version 2.7, 3.3 and 3.4, but your version of Python is 3.5
The error makes it obvious that you need an older version of Python. I decided to use 2.7. To do that, I created another environment with Python 2.7:
conda create -n py27 python=2.7 anaconda
The guidelines to managing Python environments are here.
The next step was checking what environments were available:
conda info --envs
And activating Python 2.7 (py27):
source activate py27
Install Python-MATLAB engine
To install the engine connecting both languages: go to your MATLAB folder, find the Python engine folder and install setup.py. This can be done in the following way:
Change your working directory to where your MATLAB lives: cd "MATLABROOT/extern/engines/python"
If you don’t know where your MATLAB is installed, use: locate matlab
Then install the engine (it will only work with MATLAB >=2014b):
That should do the job. Now open new Jupyter notebook:
jupyter notebook
To check whether you can find MATLAB among the available engines (top right corner):
Now check whether you can actually run the notebook. Initially, when I tried using Python 3.5, I could see MATLAB among the options but the kernels would die each time I tried running the MATLAB code. Moving to Python 2.7, as described in this tutorial, solved the problem.
If all works fine then the following notebook should generate correctly:
Even though I’m getting the MetaKernelApp error, the notebook continues to work correctly: [MetaKernelApp] ERROR | No such comm target registered: jupyter.widget.version
To leave the environment used to run the notebook, simply type:
source deactivate
Notes
Initially, I struggled a bit with making it all work so in the meantime I also tried installing Octave (a free equivalent of MATLAB). I’m not sure whether that installation helped me with running MATLAB within Jupyter.
While trying to install the engine I came across several errors. I guess that most of them were related to my OS configuration and all of them were solved by searching for the error message. One of the errors was:
Error:
[I 00:58:19.847 NotebookApp] KernelRestarter: restarting kernel (3/5)
/home/eub/anaconda3/bin/python: No module named matlab_kernel
This was due to installing the Python engine in the wrong environment (i.e. my default Python 3.5). It was solved by activating Python 2.7 and using it to install the Python-MATLAB engine.
I think that there is an alternative way to activate MATLAB in Jupyter, without Anaconda, would be to explicitly point the installer to the Python version that supports the Py-MATLAB engine.
In my case: sudo ~/anaconda/pkgs/python-2.7.13-0/bin/python2.7 setup.py install
You might also want install the engine in a non-default location. In that case, MATLAB has a solution to that problem and suggested installing Python in the home directory.
There is another Jupyter kernel (imatlab) engine that supposedly works with Python 3.5 and MATLAB R2016b+ but I haven’t tested it myself. As long as my current configuration works, I’m not planning to go through the hell of installing dependencies again.
After using R notebooks for a while I found it really unintuitive to use MATLAB in IDE. I read that it’s possible to use MATLAB with IPython but the instructions seemed a bit out of date. When I tried to follow them, I still could not run MATLAB with Jupyter (spin-off from IPython).
I wanted to conduct analyses of electroencephalographic (EEG) activity and the best plug-ins to do it (EEGLAB and ERPLAB) were written in MATLAB. I still wanted to use a programming notebook so I had to combine Jupyter and MATLAB.
I spent a bit of time setting it all up so I thought it might be worthwhile to share the process. Initially, I had three version of MATLAB (2011a, 2011b, and 2016b) and two versions of Python (2.7 and 3.3). This did not make my life easier of Windows 7.
Eventually, I only kept the installation of MATLAB 2016b to avoid problems with paths pointing to other versions. MATLAB’s Python engine works only with MATLAB 2014b or later so keeping the older versions could only cause problems.
Instructions
Install Anaconda (2.7)
Install MATLAB (>=2014b) - if you are a student then it’s very likely that your university bought a license. There is also a free MATLAB-like language called Octave, but I have not used with Jupyter. Apparently, it is possible to combine Octave with Jupyter. I’m going to focus exclusively on MATLAB in this post.
Install MATLAB’s Python engine - run as admin and follow the steps on the official site.
Once the engine was installed, I could move to installing metakernel, matlab_kernel, and pymatbridge. Go to Anaconda prompt (run as admin) and run pip install metakernel
In the Anaconda prompt run pip install matlab_kernel - this will use the development version of the MATLAB kernel.
Run pip install pymatbridge to install a connector between Python and MATLAB.
… voilà!
MATLAB should now be available in the list of available languages.
Once you choose it, you can start using it in a Jupyter notebook:
Issues
Obviously, thing were not always this smooth. Initially, I ran into problems with installing MATLAB’s Python engine. The official website suggested running the following code: cd "matlabroot\extern\engines\python"
python setup.py install
Which I did but it resulted in an error:
Luckily, the error message was clear so I had to point Python to run the 64-bit version. I double-checked my versions with: import platform
platform.architecture()
Which returned 64-bit as expected:
Using a command with full path to Python solved the problem:
Summary
I hope this will be useful. I have been messing with other issues which were pretty specific to my system so I did not include them here. Hopefully, these instructions will be enough to make MATLAB work with Jupyter.
PS: I have also explained how to use MATLAB with Jupyter on Ubuntu.
During the development of another R package I wasted a bit of time figuring out how to add code coverage to my package. I had the same problem last time so I decided to write up the procedure step-by-step.
Provided that you’ve already written an R package, the next step is to create tests. Luckily, devtools package makes setting up both testing and code coverage a breeze.
Let’s start with adding an infrastructure for tests with devtools: library(devtools)
use_testthat()
Then add a test file of your_function() to your tests folder: use_test("your_function")
Then add the scaffolding for the code coverage (codecov) use_coverage(pkg = ".", type = c("codecov"))
After running this code you will get a code that can be added to your README file to display a codecov badge. In my case it’s the following: [](https://codecov.io/github/erzk/PostcodesioR?branch=master)
This will create a codecov.yml file that needs to be edited by adding: comment: false
language: R
sudo: false
cache: packages
after_success:
- Rscript -e 'covr::codecov()'
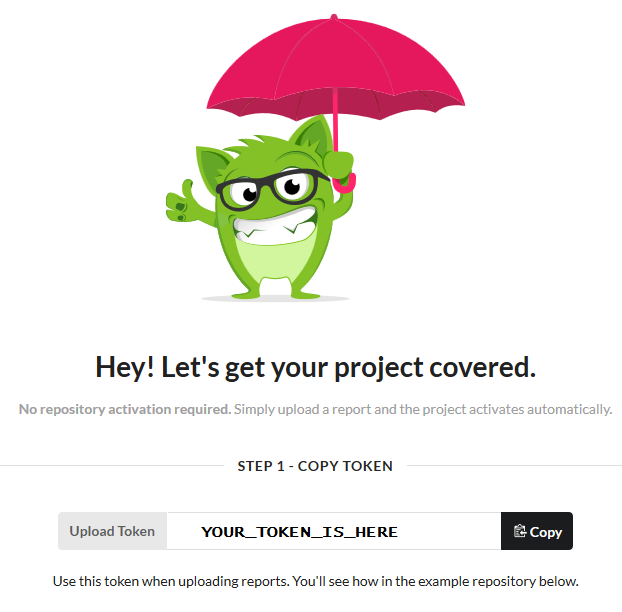
Now log in to codecov.io using the GitHub account. Give codecov access to the project where you want to cover the code. This should create a screen where you can see a token which needs to be copied:
Once this is completed, go back to R and run the following commands to use covr:
The last line will connect your package to codecov. If the whole process worked, you should be able to see a percentage of coverage in your badge, like this:
Click on it to see which functions are not fully covered/need more test:
I hope this will be useful and will save a lot of frustrations.
The easiest way to plot ETG-4000 data in R is by using plot_ETG4000() from fnirsr package. However, if you want to explore your data in more detail, then an interactive plot is more appropriate.
I used dygraphs package to create the chart below. In case of using many channels, the colours in the legend can get a bit mixed up like in my example. I haven’t figured out yet how to add a custom colour palette that could deal with multiple channels.
One way or another, this code snippet should be enough to start generating interactive charts. I haven’t added the interactive chart to the main plotting function (i.e. plot_ETG4000) but I might do it in future releases.
The code used to generate the chart is here:
PS: The dygraph generated correctly in the interactive window, when using R notebooks, and when knitting. When I Saved as Web Page from RStudio, I got a header error that I had to clean by removing a tag (<!DOCTYPE html>) from the generated html file.
I haven’t worked on fnirsr (my R package for analysing fNIRS data) for a while so I thought it’s time for some improvements. I read a great introduction to Travis CI and decided to make it work this time. After running R CMD check (and devtools::check()) several times to fix multiple bugs, I finally got to see that lovely green badge 🙂
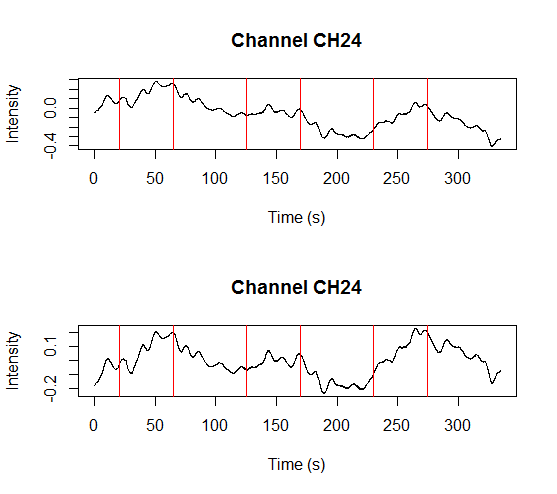
The package still needs more testing, but so far it does its job. On top of that, I finally added a function that removes a linear trend from an fNIRS signal:
For more details and the latest updates see the project’s GitHub page.
CRAN, here I come!