In my previous post I described how to split audio files into chunks using R. This time I wanted to use Python to prepare long audio files (.mp3) for further analysis. The use case would be splitting a long audio file that contains many words/utterances/syllables that need to be then analysed separately, e.g. recorded list of words.
The analysis described here was conducted on Linux (Ubuntu 16.04) and it should be fairly similar on MacOS, but Windows would require quite a few ammendments.
The first step was to turn the original .m4a files into .mp3 and to extract the segment I was interested in. I used ffmpeg for these tasks. This can be skipped if your files are already clean.
ffmpeg -i P17.m4a P17.mp3
ffmpeg -i P17.mp3 -ss 00:17:50 -to 00:23:30 -c copy P17_trim.mp3The second command created a copy of the original .mp3 file and extracted the segment between 17 min 50 sec and 23 min 30 sec. That’s where speech was recorded in my file.

The continuous audio file that I used contained repeated utterances of the same syllable. Use the code below to split this file into segments. Silence detection is conducted using Support-vector machine (SVM):
Install pyAudioAnalysis and run on the command line:
python pyAudioAnalysis/pyAudioAnalysis/audioAnalysis.py silenceRemoval -i P17_trim_short.mp3 --smoothing 1.0 --weight 0.3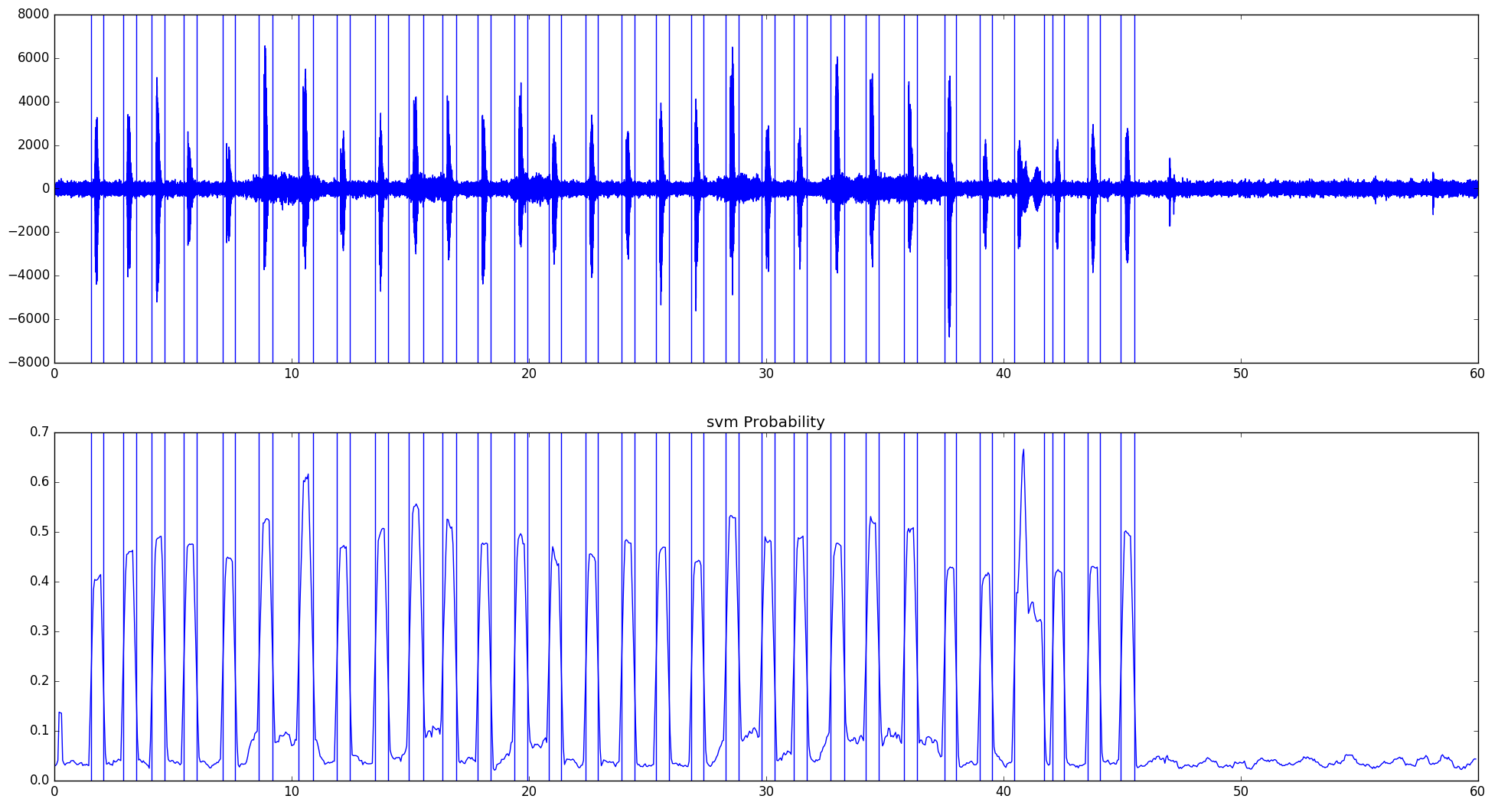
The result is a list of sliced wav files. The names contain timings of the boundaries.

All files in a given directory can be split using the following script:
Make sure to point the script to the directory where audioAnalysis.py lives. Modifying smoothing and weight parameters will lead to different effects so this should be adjusted depending on a type of audio recording. By default the script will show a pop-up window with the suggested split. This is very useful for monitoring data quality. The Python script can be used from the command line with:
python split_continuous_audio.py