One of my latest tasks at work was to analyse data related to Brexit referendum results and the UK housing market.
Luckily, all but rental data (acquired from Zoopla) was publicly available. Property prices and rental prices needed some wrangling as Land Registry doesn’t provide information about Local Authority districts, and that was the unit used by The Electoral Commission. LA districts are not a default geographic category in Tableau (version 9.3.5) but the official blog has recently featured a post demonstrating how to use non-standard mapping.
The final result was a map (below) and a press release. This is another housing market analysis that gained a lot of media coverage, among others by International Business Times, Business Insider, and Mortgage Introducer.
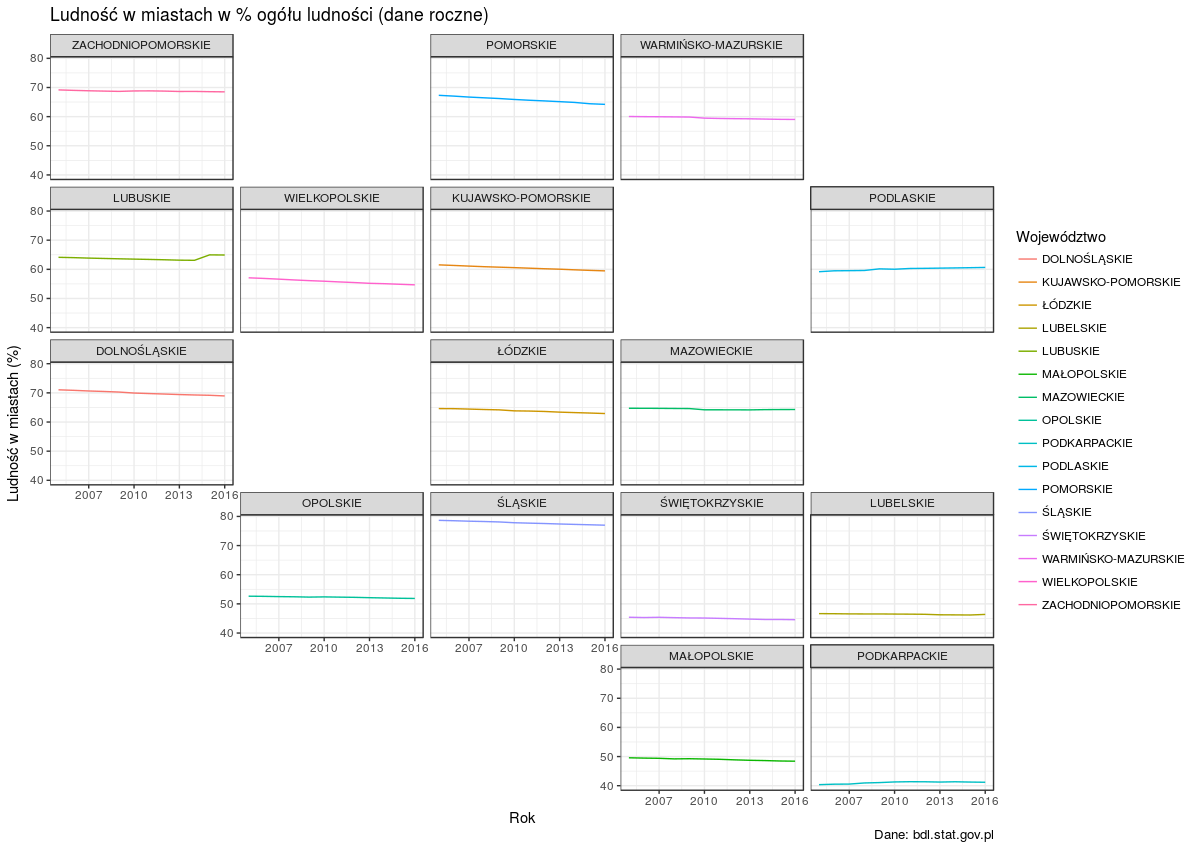
I wanted to dig deeper into the relationship between the voting pattern and the housing market information so I created the following bar charts:
Once the data is visualised in this way it becomes rather obvious that the areas where house prices and the capital gains (yearly average, in the last six years) were the highest, were also the ones that were the most likely to vote remain. The situation is much more difficult to interpret when the the results are sorted by the rental yields. In that case the voting pattern is not that clear anymore.
The scatter plots (and overlapping trend lines) make it easier to see the positive correlation between the percentage of people voting remain and the following variables: median house price (2016), median rental price (2016), and capital gains (yearly, across 2010-2016). This means that as the percentage of remain voters increases, so do the variables mentioned. This relationship did not hold for rental yields where it doesn’t seem to be any relationship between the two.
The Guardian and BBC conducted similar analyses comparing voting patterns to demographic variables.